Our system learns a Single Instructable Motion Prior from a diverse reference motion dataset.
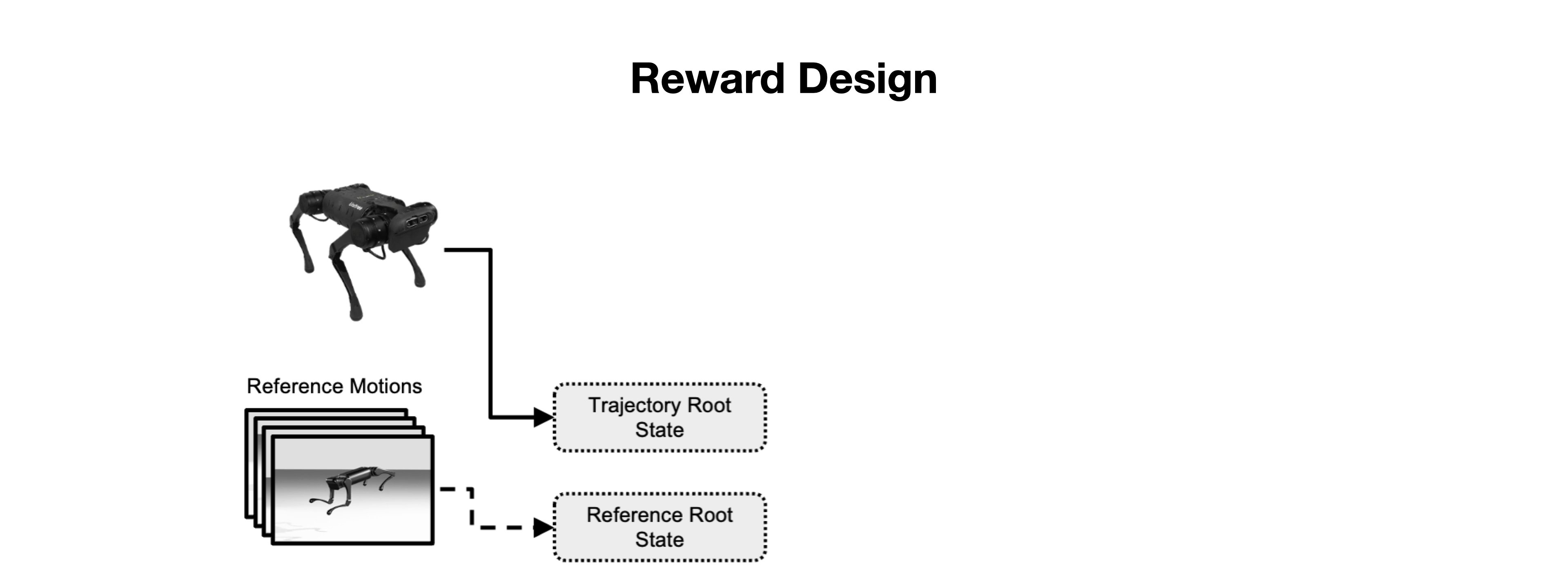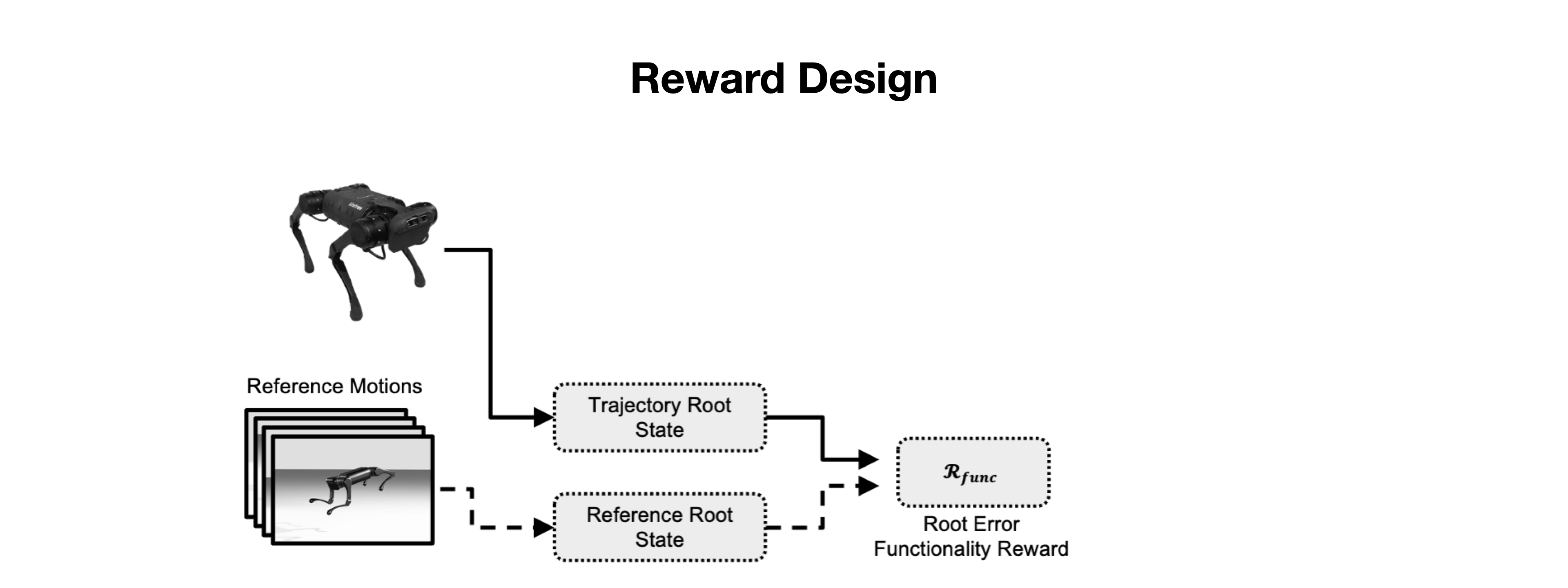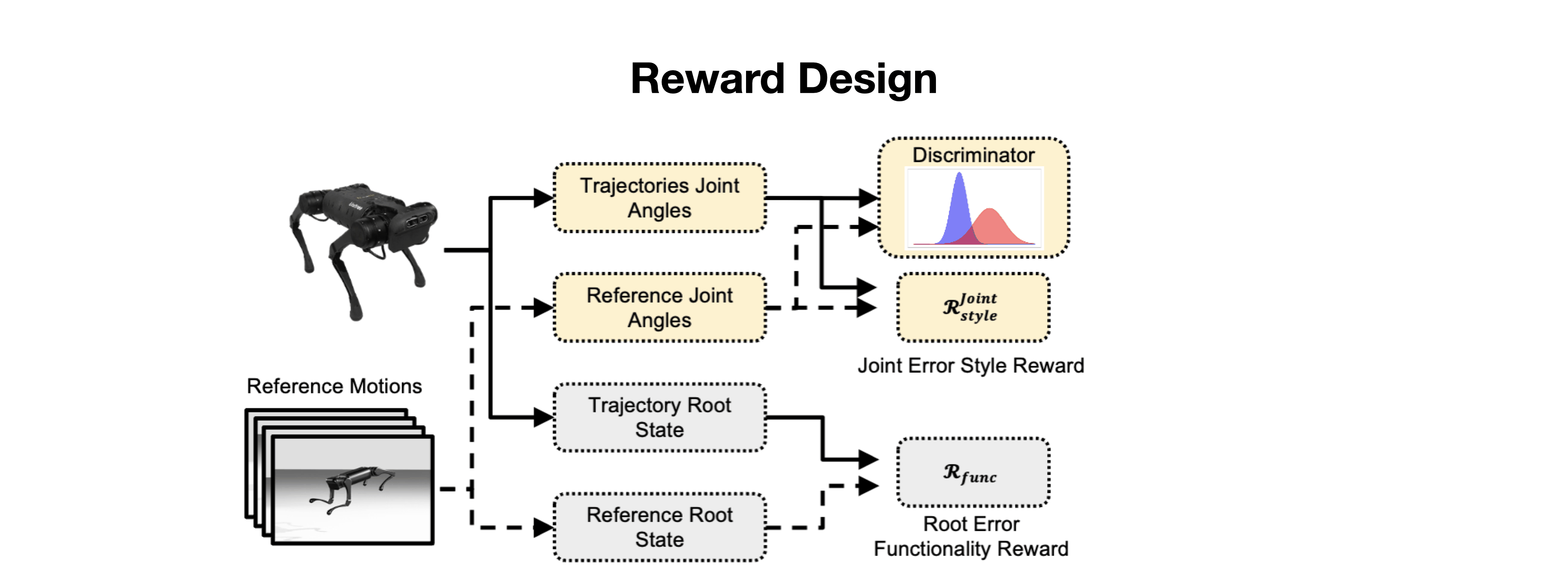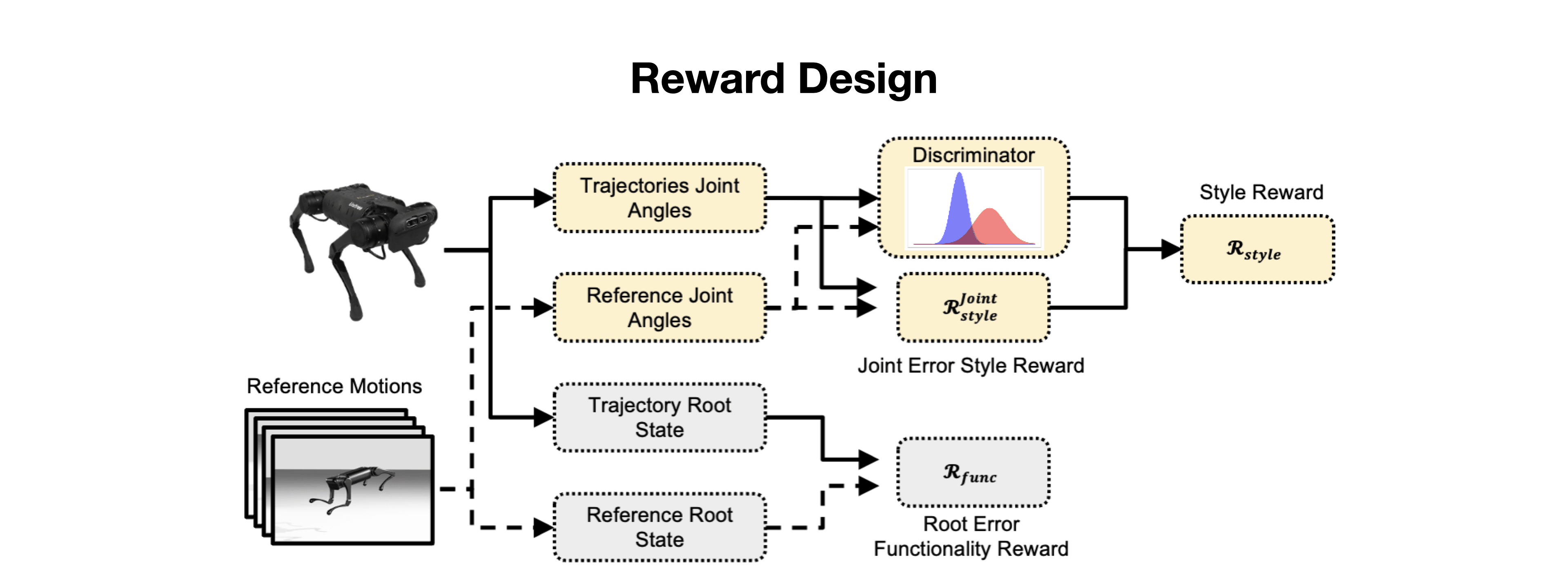
We present the Versatile Instructable Motion prior (VIM), designed to acquire a wide range of agile locomotion skills concurrently from multiple reference motions. The development of our motion prior involves three stages: assembling a comprehensive dataset of reference motions sourced from diverse origins, crafting a motion prior that processes varying reference motions and the robot's proprioceptive feedback to generate motor commands, and finally, utilizing an imitation-based reward mechanism to effectively train this motion prior. Given the formulation of our motion prior, the robot learns diverse agile locomotion skills with our imitation reward and reward scheduling mechanics. Our reward offers consistent guidance, ensuring the robot captures both the functionality and style inherent to the reference motion.
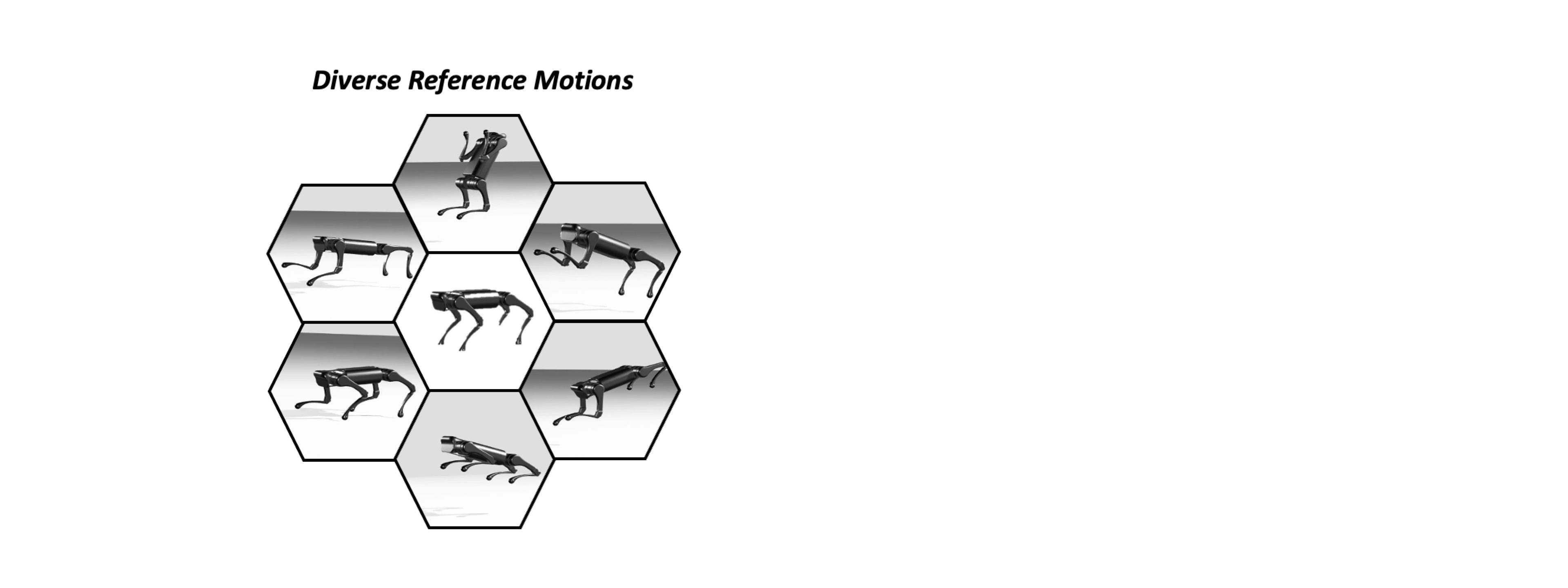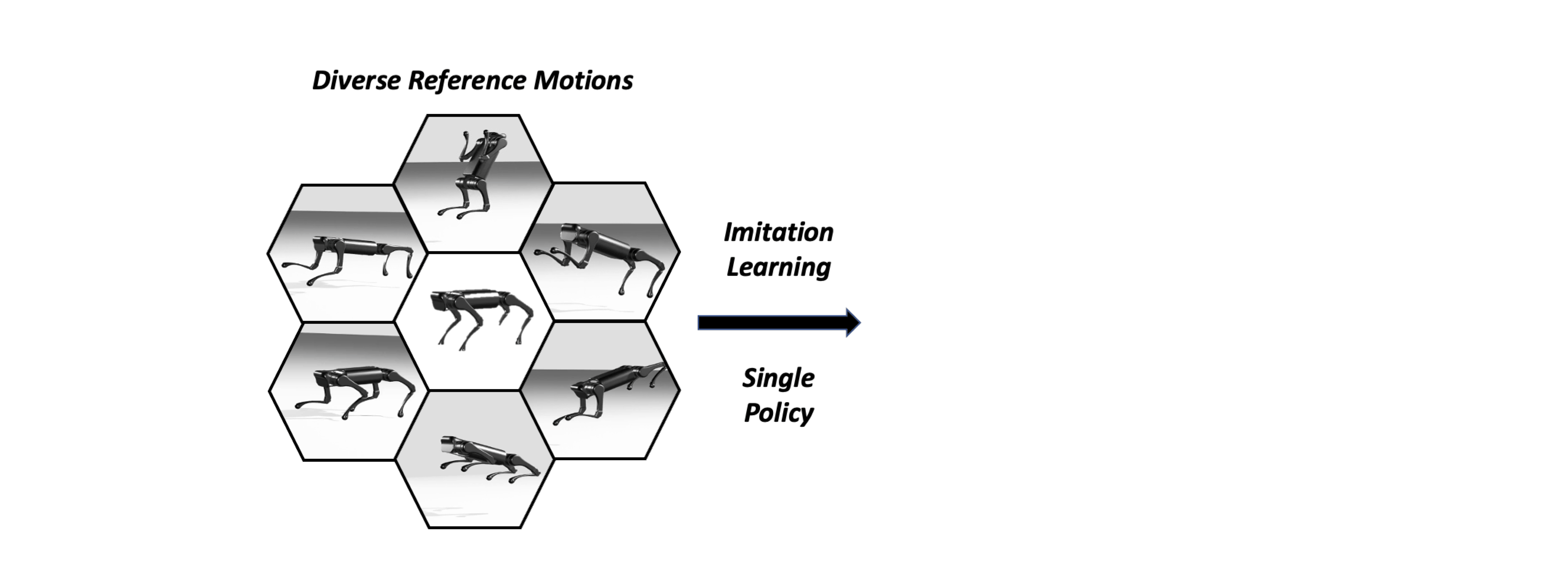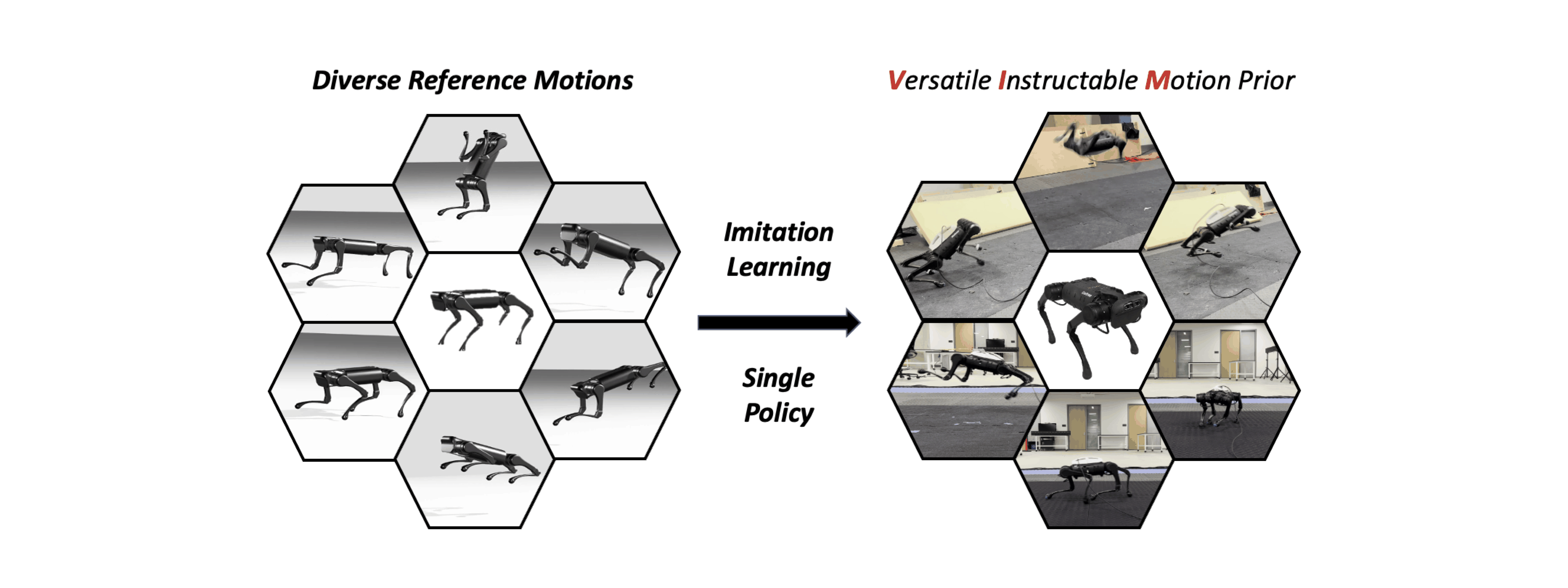
Our motion prior consists of a reference motion encoder, and a low-level policy. Reference motion encoder maps varying reference motions into a condensed latent skill space, and low-level policy utilizes our imitation reward, reproduces the robot motion given a latent command.

Given the formulation of our motion prior, the robot learns diverse agile locomotion skills with our imitation reward and reward scheduling mechanics. Our reward offers consistent guidance, ensuring the robot captures both the functionality and style inherent to the reference motion.